


3) Esempi di utilizzo
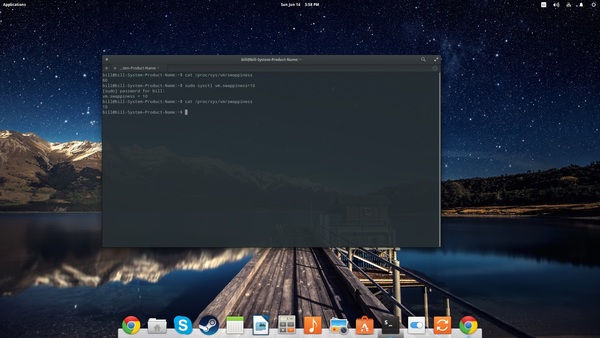
Il più semplice dei controlli da far fare a fdupes è all’interno di una cartella senza passargli alcuna opzione particolare:
fdupes /percorso/di/controllo

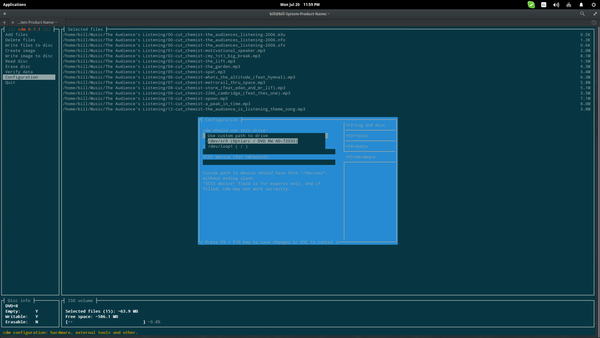
In questo modo fdupes ci segnalerà gli eventuali file presenti in numero maggiore di uno disponendoli uno per ogni riga e lasciando una riga tra doppioni di file differenti; nel caso specifico è stato cambiato il nome a due file, però fdupes non si è fatto “ingannare” e ci ha fornito i file effettivamente in duplice copia. Se passiamo a fdupes l’opzione -d gli stiamo dicendo che può cancellare i file:
fdupes -d /percorso/di/controllo

Le opzioni sono quelle di preservare il file numero uno, il file numero due o entrambi; in sostanza digitando 1 e premendo Invio verrà cancellato il file che nell’elenco è indicato con “[1]” e così dicasi per il secondo etc. Fatta la scelta sul primo file, si passa al secondo file trovato come doppione e così via. In quanto calcolo puro, il programma è piuttosto veloce nella verifica e grazie proprio a questa caratteristica diventa un piacere usare fdupes quando il numero di file è piuttosto elevato mostrando tutte le sue potenzialità. Utilizzando l’opzione -sameline l’elenco dei file in più copie verranno inserite sulla stessa riga:
fdupes -sameline /percorso/di/controllo

Interessante anche l’opzione -size che mostra la dimensione dei file doppioni all’inizio di ogni riga.
fdupes -size /percorso/di/controllo

Naturalmente le opzioni si possono combinare tra loro, ad esempio valutazione della dimensione e cancellazione.
fdupes -size -d /percorso/di/controllo

Così come è possibile redirigere l’output su un file.
fdupes /percorso/di/controllo > /percorso/destinazione/file.txt

Infine, un’ultima opzione che potrebbe rivelarsi utile in presenza di mantenimento di una copia come backup, è l’utilizzo della flag -f la quale istruirà fdupes a non considerare il primo doppione del file, ma ad elencare, ed eventualmente cancellare, tutti quei file che hanno un numero di copie maggiore di due. Utilizzare la flag -r per la ricerca di file nelle sottocartelle presenti nel percorso di analisi.
E’ utile sapere che …
Per concludere va sottolineato che fdupes non è l’unica utility esistente per questi scopi, è quindi possibile una certa scelta al fine di prediligere quello che più si adatta alle nostre esigenze; ad esempio si potrebbe optare per fslint comprensivo di interfaccia grafica. Una volta scaricato e decompresso il pacchetto è sufficiente, in quanto scritto in Python, il comando:
python fslint-gui
per attivarlo al volo!

IL NOSTRO GIUDIZIO:

- A cura di Michele Petrecca