

Quando parliamo di file system, Linux rappresenta il coltellino svizzero dei sistemi operativi. Esso supporta un’ampia gamma di file system, dal journaling al clustering alla crittografia. E’ una piattaforma fantastica per l’uso di file system sia standard che più esotici e anche per lo sviluppo di nuovi. In quest’articolo trattiamo il virtual file system (VFS) nel kernel Linux e rivediamo alcune delle più importanti strutture che legano insieme i file system.

Riprendiamo un articolo dal sito IBM Developer Works.
Architettura di base di un file system
L’architettura del file system di Linux è un interessante esempio di astrazione dalla complessità. Usando un insieme comune di API, possono essere supportati un’ampia varietà di file system su un’ampia gamma di dispositivi di memorizzazione di massa. Prendiamo, ad esempio, la chiamata si sistema per la lettura, la funzione read che consente di leggere un certo numero di byte dato un file descriptor. La chiamata di sistema read è indipendente dal tipo di file system, come ext3 o NFS. E’ anche indipendente dal particolare dispositivo di memorizzazione sul quale in file system è montato. Inoltre, quando la chiamata di sistema read viene invocata su un file aperto, i dati vengono restituiti per come ci si attende. In quest’articolo proviamo a esplorare come questo viene fatto e investighiamo le più importanti strutture dati del Linux file system.
Cos’è un file system?
Diciamo che un file system non è altro che un’organizzazione di dati e metadati su un dispositivo di memorizzazione di massa. Come detto, ci sono molti tipi di file system e dispositivi. Con tutte queste varianti ci si potrebbe attendere che l’interfaccia del file system di Linux sia implementata come un’architettura a strati, separando lo strato che riguarda l’interfaccia utente dalla sua stessa implementazione e dai driver che manipolano il dispositivo di memorizzazione di massa.
Il Mount
In Linux, l’associare un file system a un dispositivo è un processo chiamato mounting. Il comando mount è usato per connettere un file system all’attuale gerarchia del file system (root). Durante il mount, viene fornito il tipo del file system, un file system, e un punto di mount. Per illustrare le capacità del file system di Linux e l’uso del mount, creiamo un file system in un file all’interno del file system corrente. Questo viene fatto creando un file di una data dimensione usando dd (copia un file usando /dev/zero come sorgente) – in altre parole, un file inizializzato con tutti zero come mostrato di seguito:
$ dd if=/dev/zero of=file.img bs=1k count=10000
10000+0 records in
10000+0 records out
10240000 bytes (10 MB) copied, 0.415464 seconds, 24.6 MB/s
Adesso abbiamo un file chiamato file.img di 10MB. Usa il comando losetup per associare un dispositivo di loop con il file (facendolo sembrare come se fosse un dispositivo a blocchi invece di file regolare all’interno del file system):
$ losetup /dev/loop0 file.img
Con il file che adesso appare come un dispositivo a blocchi (rappresentato da /dev/loop0), creiamo un file system sul dispositivo con il comando mke2fs. Questo comando crea un secondo file system nuovo ext2 sulla dimensione definita, come di seguito mostrato.
$ sudo mke2fs -c /dev/loop0 10000
mke2fs 1.40-WIP (14-Nov-2006)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
2512 inodes, 10000 blocks
500 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=10485760
2 block groups
8192 blocks per group, 8192 fragments per group
1256 inodes per group
Superblock backups stored on blocks: 8193
Checking for bad blocks (read-only test): done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
Il file file.img, rappresentato dal dispositivo di loop (/dev/loop0), adesso è montato nel punto di mount /mnt/point1 usando il comando mount. Nota che la specifica del file system è ext2. Quando montato, possiamo trattare questo punto di mount come un nuovo file system usando un comando ls, come mostrato di seguito:
$ mkdir /mnt/point1
$ mount -t ext2 /dev/loop0 /mnt/point1
$ ls /mnt/point1 lost+found
Come mostrato di seguito, possiamo continuare questo processo creando un nuovo file all’interno del nuovo file system appena montato, associandolo con un dispositivo di loop e creando un nuovo file system su di esso.
$ dd if=/dev/zero of=/mnt/point1/file.img bs=1k count=1000 1000+0 records in 1000+0 records out
$ losetup /dev/loop1 /mnt/point1/file.img $ mke2fs -c /dev/loop1 1000
mke2fs 1.35 (28-Feb-2004)
max_blocks 1024000, rsv_groups = 125, rsv_gdb = 3
Filesystem label=
…
$ mkdir /mnt/point2
$ mount -t ext2 /dev/loop1 /mnt/point2
$ ls /mnt/point2
lost+found
$
$ ls /mnt/point1
file.img lost+found
Da questa semplice dimostrazione, notiamo quale può essere la potenza del file system di Linux e dei dispositivi di loop. Possiamo usare lo stesso approccio per creare file system crittografati con il dispositivo di loop su un file. Questo è utile per proteggere i nostri dati montando in modo transitorio i nostri file usando il dispositivo di loop che chi occorre.
L’Architettura del File System
Adesso che abbiamo visto in azione la costruzione di un file system, ritorniamo all’architettura. Vediamo il file system di Linux da due prospettive. La prima è dalla prospettiva di un’architettura di alto livello. Nella seconda, andiamo un po’ più a fondo ed esploriamo il file system dalle stutture dati principali che lo implementano.
Architettura di alto livello
La maggior parte del codice che riguarda il file system risiede nel kernel (eccetto la parte che riguarda lo spazio utente). L’architettura presente in Figura mostra le relazioni tra le principali componenti di un file system tra spazio utente e kernel.
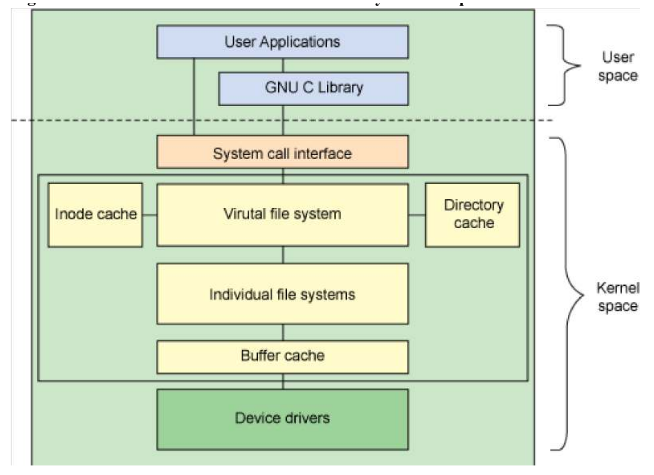
Lo spazio utente contiene l’applicazione e la GNU C Library che fornisce l’interfaccia utente per le chiamate di sistema. L’interfaccia per le chiamate di sistema agisce da switch, raccoglie le chiamate di sistema dallo spazio utente inviandole all’appropriato destinatario nello spazio del kernel. Il VFS è l’interfaccia principale verso il singolo file system che può comportarsi in modo molto diverso da uno all’altro. Esistono anche due cache per gli oggetti del file system (inodes e dentries) che definiremo tra poco. Ognuno fornisce un insieme di oggeti del file system recentemente usati.
Ogni singola implementazione del file system, come ext2, JFS e così via, esporta un insieme comune di interfacce che viene usato dal VFS. La cache memorizza le richieste tra il file system e il dispositivo a blocchi che gestisce. Questo consente alle richieste di essere memorizzate per un accesso più veloce (invece che andare ogni volta sul dispositivo fisico). La cache è gestita come un insieme di liste LRU (last recently used). Notiamo che possiamo usare il comando sync per eseguire un flush della cache sul dispositivo di memorizzazione (per forzare la scrittura di tutti i dati non ancora scritti).
Questa è la visione ad altissimo livello del VFS e delle componenti.
Alla prossima puntata!
di Giuseppe Lo Brutto - TuxJournal.net